
Apache Kafka is a powerful distributed streaming platform, but managing consumer groups at scale of 100 consumers per group can come with challenges, especially rebalancing issues that disrupt message processing.
In this blog post, VGS will walk you through a real-world scenario where our team resolved persistent Kafka consumer group rebalancing problems for a high-throughput application. By tuning configurations, analyzing metrics, and switching to the Cooperative Sticky Assignor, VGS stabilized the system, reduced broker load, and ensured uninterrupted message consumption. Let's dive into the problem, the journey to the solution, and the lessons learned.

Background: The Problem Setup
Our application, app-worker-webhook, processes messages from a Kafka topic named webhook with a pre-configured count of 100 partitions and a replication factor of 3 while running on a single Kafka 2.8.1 cluster with three brokers (IDs 1, 2, 3). We deployed 100 consumers (25 pods x 4 processes via Supervisord) using aiokafka (an async Kafka client for Python) in a Kubernetes environment on AWS.
Initially, everything seemed fine—until we hit persistent rebalancing issues:
- Consumers frequently dropped out with CommitFailedError and RequestTimedOutError on JoinGroupRequest_v2 to the group coordinator (broker 2).
- The group state was stuck in "rebalancing," disrupting message processing.
- Broker 2 showed significantly higher utilization (double the network RX packets compared to brokers 1 and 3), causing connection timeouts.
Our goal: stabilize the consumer group, reduce broker 2's load, and minimize the impact of rebalancing on all 100 consumers.

Step 1: Diagnosing the Rebalancing Problem
The team started by analyzing the root cause of the rebalancing issues.
CommitFailedError: Offset commits failed with messages like "Commit cannot be completed since the group has already rebalanced."
RequestTimedOutError: Consumers couldn't join the group, logging errors like:

Rebalancing Loop: We have leveraged Kafka's native CLI tooling to monitor the consumer group state. Using “kafka-consumer-groups.sh --describe” command showed the group assigned to our consumer as "rebalancing" for extended periods.
Using kafka-consumer-groups.sh --describe --state, we confirmed:
- Coordinator: Broker 2 (b-2.dd.dd.c10.kafka.us-east-1.amazonaws.com:9092).
- Assignment Strategy: roundrobin.
- Members: 100 consumers, matching the 100 partitions.
We also checked the topic distribution with kafka-topics.sh --describe --topic webhook:
- Leaders: Broker 1: 33, Broker 2: 34, Broker 3: 33.
- Broker 2 had slightly more leaders, but the real issue was its coordinator role.
Metrics revealed broker 2's heavy load:
- CPU Usage: Broker 2 peaked at 8.9% vs. 2-4% for brokers 1 and 3.
- Network RX Packets: Broker 2 averaged 200-300 packets/sec, peaking at 510, while brokers 1 and 3 stayed at 100-150.
- Network TX Packets: Broker 2 at 20-43 packets/sec vs. 10-20 for others.
The coordinator role was generating significant network traffic (heartbeats, commits, joins), exacerbated by SSL overhead and default broker configs (num.network.threads = 3).
Next, we assessed the consumers :
- CPU Usage: Average cpu usage across all were 48.8%
- Memory: Average memory usage across all was 58.2%
Based on the resources, we did not find an issue that causes concern about the consumers terminating.
Naturally, our first naïve attempt was to increase the number of producers, such that we provide relief on an ongoing basis. We scaled the number of consumers to 400 (from 100 originally). This did not provide the outcome we were expecting. In fact, adding 300 more consumers added more network overhead and pressure to the brokers, as it now needed to coordinate the work assignment between 400 consumers vs 100! Furthermore, since we only have 100 partitions, the ideal config to enable maximum parallelism is 1 consumer app per 1 partition available per topic. This prompted us to revert to our original config of 100 consumers.
Re-evaluating our findings, we did notice that certain consumers were busy for extended periods with high cpu/memory usage. This caused the consumer to take a long time to process a set of fetched records from the kafka queue, which in turn caused kafka to mark them dropped and remove them from the consumer group.
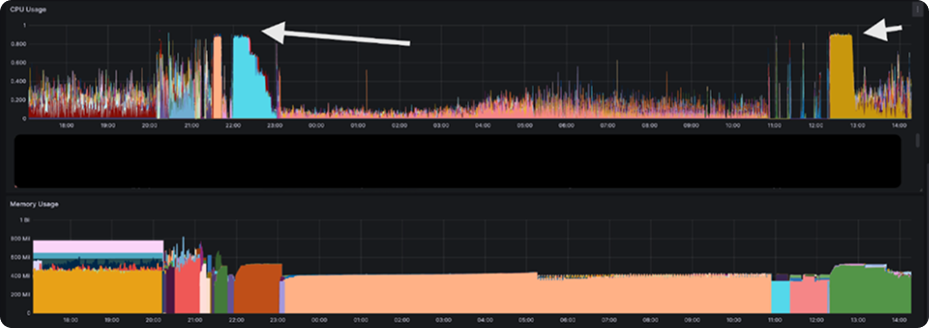
Although not optimal, it is not of concern as this type of behaviour can happen in any distributed system.
However, what aggravated the problem was what happened after the consumer finished processing the records.
After completing the work, consumers connected to kafka to be assigned the next set of tasks. However, they were marked dropped from the cluster's point of view. This meant that now there needs to be renegotiation of adding the workers back into the consumer group of 100, which took a long time to settle. This repeated anytime any pod would fail either organically (due to processing errors or app crashing) or due to it taking too long. Hence, most of the time was spent in negotiating the connection between consumers and the cluster, which meant no notification was sent out, and worse, the backlog of notifications to be processed kept growing!

Step 2: Initial Fixes to Stabilize the Consumer Group
Before switching assignors, we needed to stop the rebalancing loop and address broker 2's timeouts.
- Problem: Consumers were timing out during group joins (default session_timeout_ms = 30,000ms was too low for 100 consumers starting simultaneously).
- Solution: Doubled it to 60,000ms (60s) and adjusted heartbeat_interval_ms to 20,000ms (1/3 of session timeout).
Code

Result: Group joins stabilized, reducing premature coordinator evictions.
- Problem: RequestTimedOutError on JoinGroupRequest_v2 indicated broker 2 wasn't responding within the default timeout (60s).
- Solution: Increased request_timeout_ms to 120,000ms (2 minutes) to tolerate broker delays.
Code

Result: Consumers stopped marking the coordinator as dead, and the group reached a "Stable" state.
- Problem: Potential issues with long processing times between polls, leading to timeouts.
- Solution: Increased max_poll_interval_ms from 300,000ms to 600,000ms and reduced max_poll_records from 10 to 5. This allows more time for processing and reduces the batch size.
Code

Result: Increased stability by allowing more time for message processing and reducing the load per poll.
These changes stopped the rebalancing loop, but broker 2's load remained high, and any rebalance still impacted all consumers due to the round-robin strategy.

Step 3: Switching to Cooperative Sticky Assignor
While the group was stable, the team wanted to minimize the impact of future rebalancing events (e.g., pod restarts, scaling). The round-robin strategy uses an Eager rebalancing protocol, where all consumers drop all partitions and reassign them—a costly operation for 100 consumers. Furthermore, this rebalancing happens when ANY consumer from the consumer group drops or rejoins the group. This would cause issues since most of the time, the consumer group will rebalance when they would instead be working on sending the notifications.
The Cooperative Sticky Assignor (available in Kafka 2.4.0+ and aiokafka 0.12.0 for completed implementation). This strategy offers the following benefits:
- Incremental Rebalancing: Consumers only release partitions they no longer own, keeping others active.
- Sticky Assignments: Preserves existing assignments, reducing churn.
- Reduced Load: Fewer requests to the coordinator (broker 2) lower RX/TX packet spikes. This relieves the Kafka brokers from the overhead imposed by the consumer rebalancing activity.
At VGS, we use an in-house Python library derived from the aiokafka library. This facilitated our leveraging a battle-hardened upstream library and building our customizations on top of it. While the default strategy of “Round-robin” has been battle-hardened for a while, the Sticky strategy is implemented fully in aiokafka 0.12.0. Internally, we were using 0.8.0 of the aiokafka.
In addition, we use a poetry dependency management system with our Python libraries. Since the internal package had other dependencies besides aiokafka, this task was far from straightforward. To make matters more complicated, the parameter for selecting the default strategy needs to be a class type, as opposed to a string or int, which makes things easy to pass.
To solve these challenges, we decided to split the changes into 3 categories and implement them in the relevant packages. The following summarizes the work done to make this happen:
- VGS-Kafka-Utils- This package was updated and contains minimal dependencies, including aiokafka. This makes it easy to update the package in the future, as we need to.
- App-Worker - This is a package that imports the VGS-Kafka-Utils and imposes other dependencies that are needed at the base layer. This means we can abstract all dependencies we need for things like observability. This is also a package that acts as controller to the next service.
- App-Webhook-Worker - This is the package that handles validation of information and sends the notifications to the webhook endpoint as configured by our customers. This package imports the previous package and uses VGS-Kafka-Utils by lineage. This means we can set the parameter to dynamically switch the strategies using a higher level variable, which previously needed to be rebuilt.
After upgrading aiokafka, we need to import the assignors we want to use in our base package as such:

Then, we can use the appropriate assignor as necessary. We rebuilt the app worker with the VGS-Kafka-Utils package that we updated above.
In the next step, we import the app-worker package in the app-webhook-worker package and modify the code with the config, where we can specify the type of assignor we need to use:

Updated Code

Key Changes
- Added CooperativeSticky: Set partition_assignment_strategy=[Sticky] to enable the new assignor.
- Ensured Compatibility: Verified Kafka 2.8.1 and aiokafka (version ≥0.12) support this assignor.
Results
- Stable Consumer Group: kafka-consumer-groups.sh --describe --state now consistently shows "Stable" with CooperativeSticky as the strategy.
- Reduced Rebalancing Impact: Simulating a pod failure (e.g., kubectl delete pod) resulted in minimal disruption—only affected consumers reassigned partitions.
- No More Timeouts: No RequestTimedOutError or CommitFailedError in consumer logs.

Lessons Learned
- Monitor Broker Load: Use metrics (CPU, network RX/TX) to identify coordinator bottlenecks early. Broker 2's high packet count was a red flag.
- Instrument / Monitor consumer metrics: Consumers do logical work on fetched records. Understanding CPU and memory usage on the pods, along with time spent doing work on fetched records, helps us in understanding the bottleneck, optimizing these, and tuning the parameters passed to the consumers (see implementation section)
- Tune Consumer Timeouts First: Increasing session_timeout_ms and request_timeout_ms can stabilize a group while you investigate deeper issues.
- Use Cooperative Sticky for Large Groups: With 100 consumers, the Cooperative Sticky Assignor significantly reduces rebalancing overhead.
Below, we can see the effect of tuning the parameters on the throughput of the webhook worker subsystem.
Before tuning the setting, due to rebalancing issues, we only serviced 13 req/second and the rate is volatile as depicted below:

After tuning the parameters and applying the above lessons, we have 10x the rate, to 135 req/second, and the load is sustained (i.e. not volatile).

The CPU and memory usage across the consumer group stayed relatively the same, but the work assigned was more distributed across various consumers.
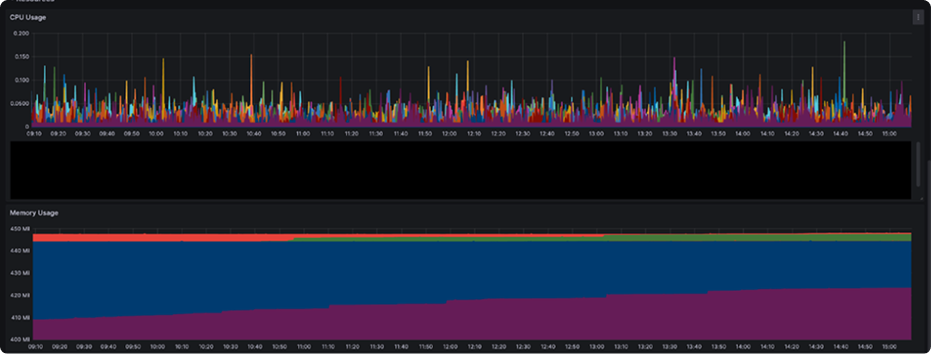
Overall, these measures resulted in more evenly distributed load across the consumer group, which limited the risk of a single consumer instance timing out, causing rebalancing issues that result in delayed notifications and significant growth of backlog.
Conclusion
Switching to the Cooperative Sticky Assignor, combined with consumer and broker tuning, transformed our Kafka consumer group from a rebalancing nightmare to a stable, efficient system. If you're facing similar issues with large consumer groups, start by analyzing metrics, tuning timeouts, and adopting incremental rebalancing strategies like CooperativeSticky. Your consumers (and your brokers) will thank you!
 Ramin Ranjbar
Ramin Ranjbar  Jimit Patel
Jimit Patel 

